Blog
Embedding One Million 3D Models: Where CAD Meets AI
4 min read


This experiment was initially completed in November 2023. In light of the recent enthusiasm for applying AI to 3D design, we have decided to publish and open-source the dataset.
AI Research Progress in 3D Design
The intersection of artificial intelligence (AI) and 3D design is an active, rapidly evolving research domain. Significant progress is being made with LLMs and transformer-based architectures. While it’s software engineers who are seeing their workflows disrupted today, the technologies underpinning AI will transform all knowledge work. This includes mechanical engineering, industrial design, and anyone who develops 2D and 3D models.
In 2025, models improved their vision, spatial understanding, reasoning, and can now use computers and other software to complete long tasks without supervision.
- Generative AI, including 3D diffusion models, can create highly accurate meshes from images or descriptions of objects.
- LLMs can generate the precursor formats to parametric design, especially open formats like Open CASCADE.
- Vision Language Models (VLMs) have improved visual accuracy and spatial reasoning, enabling them to understand drawings and 3D renders.
- General-purpose agents can now take action on a user's computer, navigate file systems, and use browsers and CAD software.
Reality vs. Hype
Many people, observing the rapid automation of software engineering, assume that design will eventually adopt a text-based workflow as well. While there is some truth to this, several factors make that outcome unlikely.
- Most design constraints are implicit or exist outside of design software (manufacturability, customer constraints, GD&T, etc.)
- Design offers simpler primitives but a richer search space. As compared to code, design tools are easier to learn but harder to master.
- Design has less training data. Whereas LLMs have learned from trillions of lines of high-quality open-source code, the richest design repositories are private.
- Design is highly visual. Models need excellent spatial reasoning and a strong sense of aesthetics.
- Design lacks formal verifiability. Code repos have tests that either run or pass. In design, many constraints are implicit. The exception may be in cases where a single constraint (ex. strength, weight, heatsink effectiveness, lift on an airfoil, CNC time, etc.) drives the outcome.
However, it would be equally naive to assume that AI will never be able to do the job of a mechanical engineer. We do expect future CAD software to accelerate manual workflows, including:
- Initial ideation and rapid prototyping.
- Searching for existing parts within an organization.
- Creating variants of parts and assemblies.
- Resolving under- or over-determined sketch constraints.
- Analyzing failure modes and automating testing.
- Setting up simulations, for example, by selecting the correct boundary conditions.
Embedding One Million Parts
Embeddings: The Building Blocks of AI
Vector embeddings are large lists of floating point numbers (usually a few hundred or thousand numbers long) that represent the relatedness of things like text, images, or video. Small distances between two embeddings mean the inputs are highly related and large distances mean they are dissimilar. Embeddings are one of the fundamental building blocks of almost all AI systems. This measure of closeness allows AI to:
- Search a large corpus for relevant documents
- Recommend similar content
- Generate images that adhere to a specific prompt
- Detect anomalies
- And much more
Unfortunately, there are no high-quality embedding models specifically for parametric 3D data. Let’s fix that!
Methodology
For this research project, we opted to use ABC-Dataset, a publicly available dataset of one million parametric parts. These parts were initially designed in OnShape, and are offered in a variety of parametric b-rep formats (.STEP, .PARA, .SHAPE) as well as mesh (.STL).
Rather than train our own embedding model, we are interested in a shortcut. Indeed, this shortcut is the central research question:
“How effective are VLMs and text embeddings at mapping relatedness in 3D models?”
So instead of going from 3D to embedding directly, we render the part, caption the render, and use the text embedding as the basis.
 Sample Image and Caption
Sample Image and Caption
 Pipeline
Pipeline
We can anticipate some drawbacks in this approach.
- First off, the render is limited both in its resolution and viewing angle, meaning highly detailed parts may not be captured accurately.
- This pipeline also loses the notion of size and scale. Two parts, one a scaled version of the other, are likely to be embedded in the same space, whereas they should be highly similar in only some dimensions. One can imagine a 3D embedding model where the notion of size is captured along a single axis; sliding back and forth scales a part up and down, but otherwise doesn’t change its properties.
However, this approach enables interesting features and possibilities:
- The biggest advantage is full-text search. Users should be able to search things like “bracket for a drone motor” and get sensible results.
- All of the pipeline steps are independent: the system can be upgraded whenever new VLMs or embedding models are released, and the steps can be evaluated and benchmarked in isolation.
- The VLM system prompt can be easily updated and tuned to provide captions that include specific details like the purpose or technical name of a part, if obvious. Whereas our implementation uses unstructured captions, formats like JSON may provide certain benefits.
- We don’t need massive data or a cluster of expensive GPUs.
Results and Demo
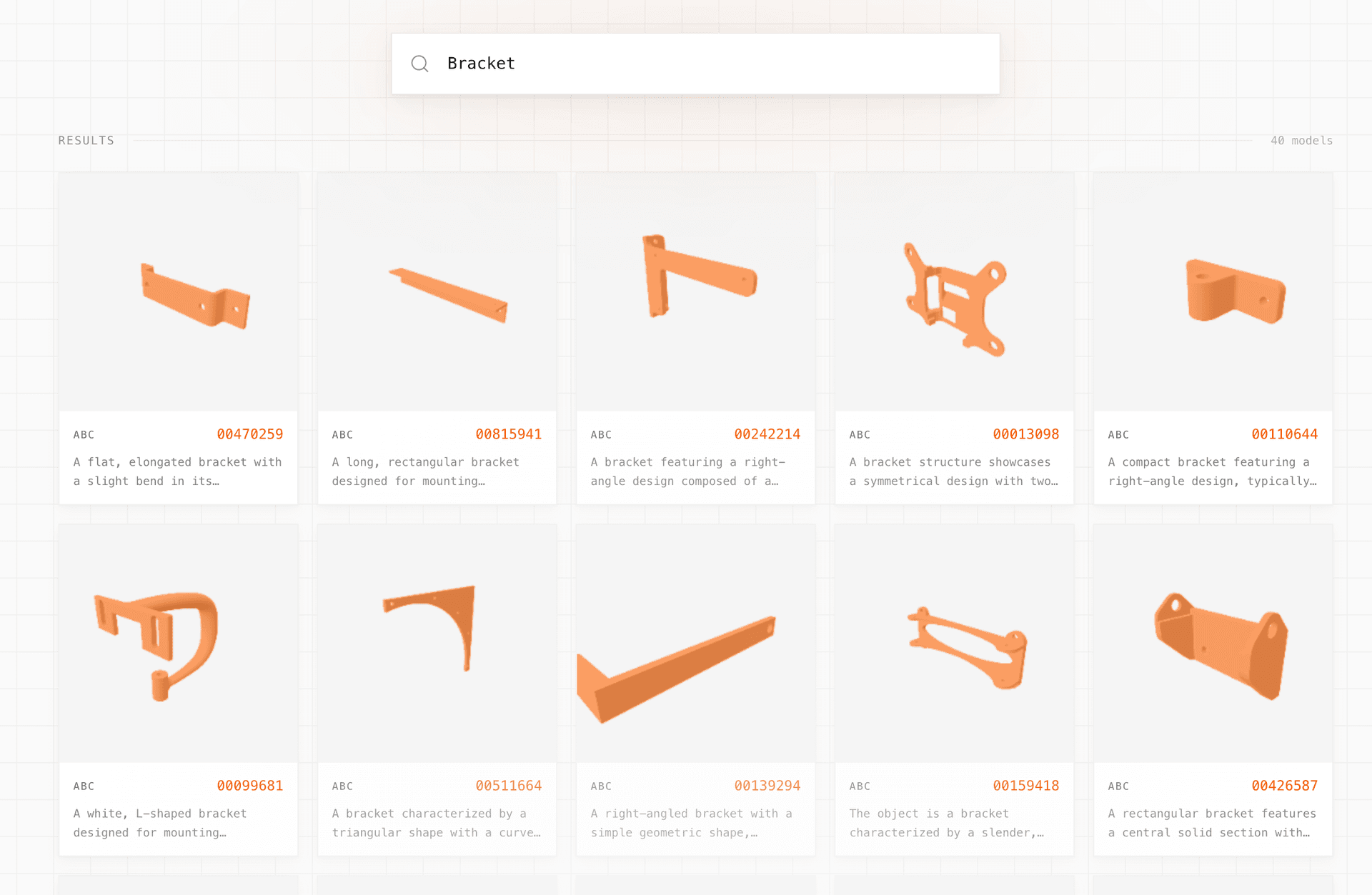
Our search demo proves that it works quite well. As anticipated, text search works beautifully, returning sensible results for even irregular or poorly formed queries. It’s worth mentioning that this is very different from 3D part libraries like Thingiverse or GrabCAD. Search in those repositories requires users to tag or annotate parts with a description, the text of which is used in search. Our system takes only an unnamed part as input, requiring no additional labelling.
A demo of the system can be found here: https://cad-search-three.vercel.app/.
 Demo of CAD Search
Demo of CAD Search
Open-sourcing this work
We will be open-sourcing all data for this project. The augmented dataset, including captions and embeddings, can be found on HuggingFace here: https://huggingface.co/datasets/daveferbear/3d-model-images-embeddings
Try finalREV today
Upload your STEP or STP files instead and receive an instant quote.
or drag and drop to upload
Uploads are secure and confidential.